3.d. Word Clouds
A popular way of visualizing the content of a corpus is to build a word cloud. There aren't many conclusions you can draw from word clouds, but they're nonetheless amusing.
First, we build the word cloud of the entire corpus, without pruning any words.
from collections import Counter
from IPython.display import Image
from wordcloud import WordCloud
import haikulib.eda.colors
from haikulib import data, nlp, utils
bag = data.get_bag_of("words", add_tags=False)
del bag["/"]
wordcloud = WordCloud(
max_words=500, width=1600, height=900, mode="RGBA", background_color=None
).generate_from_frequencies(bag)
wordcloud.to_file("all-words.png")We can see some of the interesting bits, but they're overwhelmed by words like "a", "the", "in", and "and". These words are called "stop words", and we should remove them.

bag = {k: v for k, v in bag.items() if k not in nlp.STOPWORDS}
wordcloud = WordCloud(
max_words=500, width=1600, height=900, mode="RGBA", background_color=None
).generate_from_frequencies(bag)
wordcloud.to_file("without-stopwords.png")The results are much more interesting. The resulting word cloud follows my preconceived notions about haiku, and in this particular case, they seem to be supported by evidence.
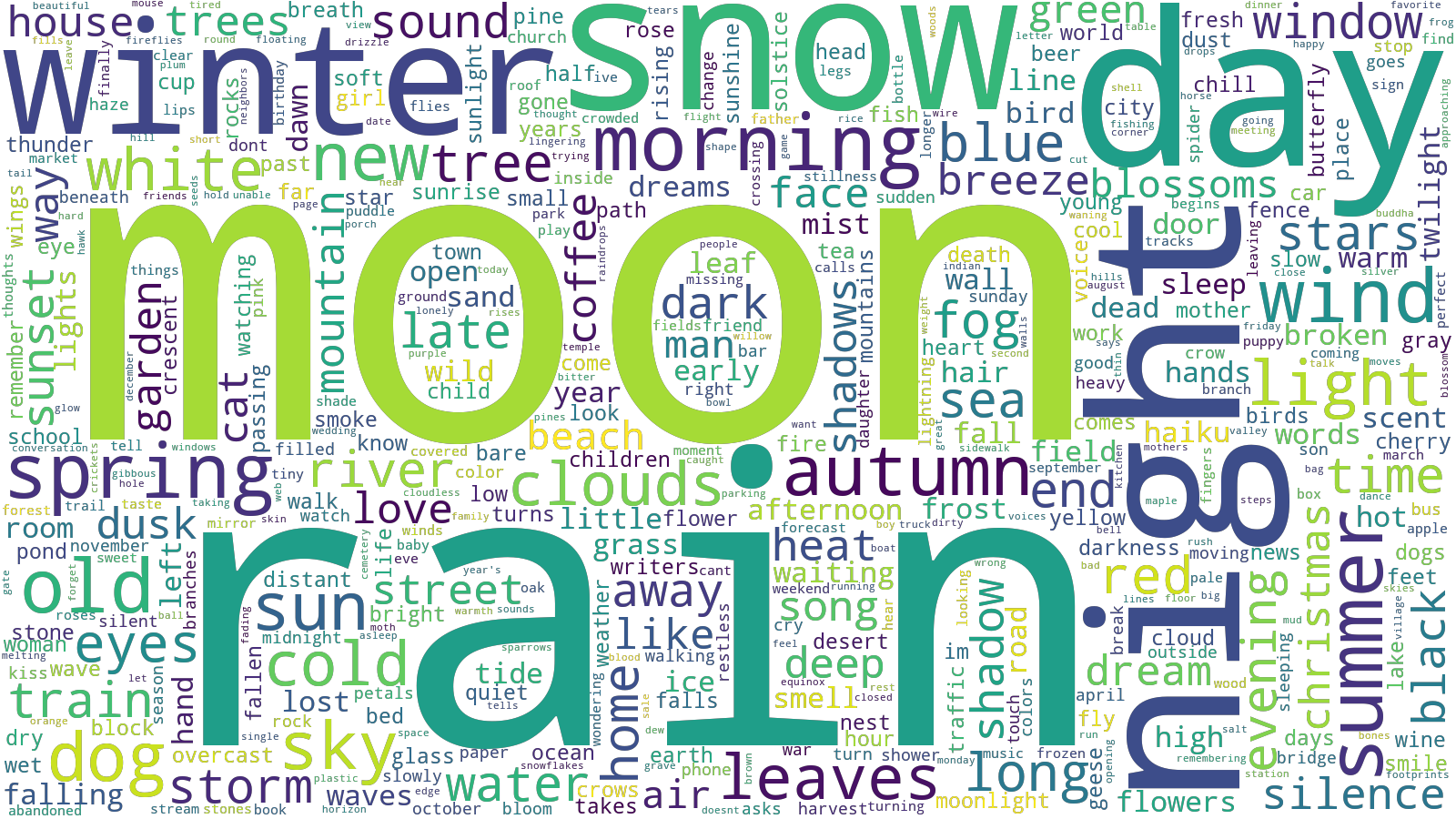
Another set of word clouds I'd like to make is the occurrence of flora and fauna in the haiku corpus.
# Form a list of haiku without the `/` symbols.
df = data.get_df()
corpus = []
for haiku in df["haiku"]:
corpus.append(" ".join(haiku.split("/")))
flower_names = data.get_flowers()
animal_names = data.get_animals()
color_counts = Counter()
color_values = dict()
_df = haikulib.eda.colors.get_colors()
for _, row in _df.iterrows():
color = row["color"]
color_counts[color] = row["count"]
color_values[color] = row["hex"]
flowers = Counter()
animals = Counter()
for haiku in corpus:
# Update the counts for this haiku.
flowers.update(nlp.count_tokens_from(haiku, flower_names, ngrams=[1, 2, 3]))
animals.update(nlp.count_tokens_from(haiku, animal_names, ngrams=[1, 2, 3]))There is a large amount of flora mentioned in the haiku, most of which are (naturally) flowers and trees.
wordcloud = WordCloud(
max_words=500, width=1600, height=900, mode="RGBA", background_color=None
).generate_from_frequencies(flowers)
wordcloud.to_file("flora.png")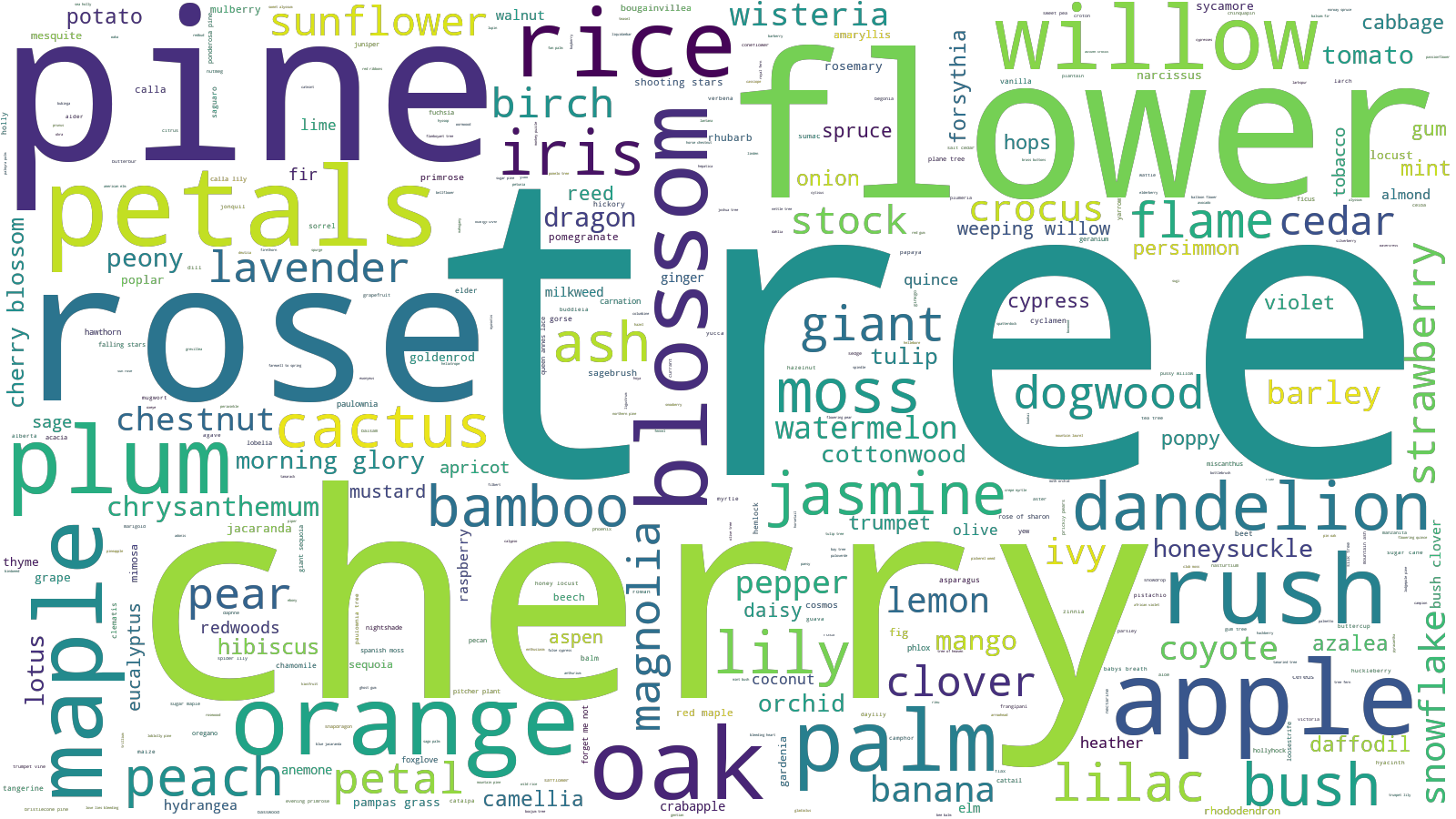
My big list of fauna also contains a number of flora, but I've done my best to filter those out.
wordcloud = WordCloud(
max_words=500, width=1600, height=900, mode="RGBA", background_color=None
).generate_from_frequencies(animals)
wordcloud.to_file("fauna.png")
Lastly, here's a simple representation of the color palette of the haiku. Note I had to modify some of the light and dark color values so that they're visible with a transparent background.
def color_words(word, *args, **kwargs):
# Black on a black background doesn't look so hot.
rgb = color_values[word]
if word in {"white", "blank", "milk", "bone"}:
rgb = color_values["snow"]
elif word in {"black", "raven", "shadow"}:
rgb = color_values["dark"]
return rgb
wordcloud = WordCloud(
max_words=500,
width=1600,
height=900,
mode="RGBA",
background_color=None,
min_font_size=7,
color_func=color_words,
).generate_from_frequencies(color_counts)
wordcloud.to_file("colors.png")